Build custom connection logic in cascading to ensure only MAP_SIDE
I have 3 cascading pipes (one connected to the other two) as described below
- LHSPipe – (larger size).

- RHSPipes – (may fit smaller size of memory).
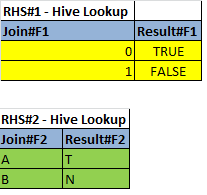
The pseudocode is as follows, and in this case involves two joins
IF F1DecidingFactor = YES Then
Join LHSPipe with RHS Lookup#1 BY (LHSPipe.F1Input = RHS Lookup#1.Join#F1) and set the result (SET LHSPipe.F1Output = Result#F1)
Otherwise
SET LHSPipe.F1Output = N/A
The same logic applies to F2 calculations.
Expected output,

THIS SITUATION FORCES ME TO USE A CUSTOM JOIN ACTION BECAUSE IF-ELSE DECIDES WHETHER TO JOIN OR NOT.
With the above in mind, I
want to make a MAP-SIDE connection (keeping RHSPipe in the memory of the MAP task node), and I’m considering the following possible solutions, each with its pros and cons. Your advice on this is needed.
Option #1:
CoGroup – We can use CoGroup and BufferJoiner to build custom join logic, followed by custom connections (actions), but this does not guarantee a MAP-SIDE connection.
Option #2:
HashJoin – It ensures a MAP-SIDE connection, but as far as I can tell, it is not possible to build a custom connection using it.
Please correct my understanding and offer your opinion to address this need.
Thanks in advance.
Solution
The best way to solve this problem (I can think of) is to modify smaller datasets. You can add a new field (F1DecidingFactor) to a smaller dataset. The value of F1Result should look like this:
Sudo code
if F1DecidingFactor == "Yes" then
F1Result = ACTUAL_VALUE
else
F1Result = "N/A"
Results table
| F1#Join| F1#Result| F1#DecidingFactor|
| Yes| 0| True|
| Yes| 1| False|
| No| 0| N/A|
| No| 1| N/A|
You can also do this by cascading.
After that, you can make a map-side connection.
If modifying a smaller dataset is not possible, then I have 2 options to solve the problem.
Option 1
Add a new field to your little pipeline, which is equivalent to your deciding factor (i.e. F1DecidingFactor_RHS = Yes). Then include it in your joining conditions. After joining is complete, you will only have values for those rows that match this criteria. Otherwise it will be empty/blank. Sample code:
Main class
import cascading.operation.Insert;
import cascading.pipe.Each;
import cascading.pipe.HashJoin;
import cascading.pipe.Pipe;
import cascading.pipe.assembly.Discard;
import cascading.pipe.joiner.LeftJoin;
import cascading.tuple.Fields;
public class StackHashJoinTestOption2 {
public StackHashJoinTestOption2() {
Fields f1Input = new Fields("F1Input");
Fields f2Input = new Fields("F2Input");
Fields f1Join = new Fields("F1Join");
Fields f2Join = new Fields("F2Join");
Fields f1DecidingFactor = new Fields("F1DecidingFactor");
Fields f2DecidingFactor = new Fields("F2DecidingFactor");
Fields f1DecidingFactorRhs = new Fields("F1DecidingFactor_RHS");
Fields f2DecidingFactorRhs = new Fields("F2DecidingFactor_RHS");
Fields lhsJoinerOne = f1DecidingFactor.append(f1Input);
Fields lhsJoinerTwo = f2DecidingFactor.append(f2Input);
Fields rhsJoinerOne = f1DecidingFactorRhs.append(f1Join);
Fields rhsJoinerTwo = f2DecidingFactorRhs.append(f2Join);
Fields functionFields = new Fields("F1DecidingFactor", "F1Output", "F2DecidingFactor", "F2Output");
Large Pipe fields :
F1DecidingFactor F1Input F2DecidingFactor F2Input
Pipe largePipe = new Pipe("large-pipe");
Small Pipe 1 Fields :
F1Join F1Result
Pipe rhsOne = new Pipe("small-pipe-1");
New field to small pipe. Expected Fields:
F1Join F1Result F1DecidingFactor_RHS
rhsOne = new Each(rhsOne, new Insert(f1DecidingFactorRhs, "Yes"), Fields.ALL);
Small Pipe 2 Fields :
F2Join F2Result
Pipe rhsTwo = new Pipe("small-pipe-2");
New field to small pipe. Expected Fields:
F2Join F2Result F2DecidingFactor_RHS
rhsTwo = new Each(rhsTwo, new Insert(f1DecidingFactorRhs, "Yes"), Fields.ALL);
Joining first small pipe. Expected fields after join:
F1DecidingFactor F1Input F2DecidingFactor F2Input F1Join F1Result F1DecidingFactor_RHS
Pipe resultsOne = new HashJoin(largePipe, lhsJoinerOne, rhsOne, rhsJoinerOne, new LeftJoin());
Joining second small pipe. Expected fields after join:
F1DecidingFactor F1Input F2DecidingFactor F2Input F1Join F1Result F1DecidingFactor_RHS F2Join F2Result F2DecidingFactor_RHS
Pipe resultsTwo = new HashJoin(resultsOne, lhsJoinerTwo, rhsTwo, rhsJoinerTwo, new LeftJoin());
Pipe result = new Each(resultsTwo, functionFields, new TestFunction(), Fields.REPLACE);
result = new Discard(result, f1DecidingFactorRhs);
result = new Discard(result, f2DecidingFactorRhs);
result Pipe should have expected result
}
}
Option 2
If you want to use the default value instead of null/blank, then I recommend that you first do a HashJoin with the default connector, and then use a function to update the tuple with the appropriate value. Something like this:
Main class
import cascading.pipe.Each;
import cascading.pipe.HashJoin;
import cascading.pipe.Pipe;
import cascading.pipe.joiner.LeftJoin;
import cascading.tuple.Fields;
public class StackHashJoinTest {
public StackHashJoinTest() {
Fields f1Input = new Fields("F1Input");
Fields f2Input = new Fields("F2Input");
Fields f1Join = new Fields("F1Join");
Fields f2Join = new Fields("F2Join");
Fields functionFields = new Fields("F1DecidingFactor", "F1Output", "F2DecidingFactor", "F2Output");
Large Pipe fields :
F1DecidingFactor F1Input F2DecidingFactor F2Input
Pipe largePipe = new Pipe("large-pipe");
Small Pipe 1 Fields :
F1Join F1Result
Pipe rhsOne = new Pipe("small-pipe-1");
Small Pipe 2 Fields :
F2Join F2Result
Pipe rhsTwo = new Pipe("small-pipe-2");
Joining first small pipe.
Expected fields after join:
F1DecidingFactor F1Input F2DecidingFactor F2Input F1Join F1Result
Pipe resultsOne = new HashJoin(largePipe, f1Input, rhsOne, f1Join, new LeftJoin());
Joining second small pipe.
Expected fields after join:
F1DecidingFactor F1Input F2DecidingFactor F2Input F1Join F1Result F2Join F2Result
Pipe resultsTwo = new HashJoin(resultsOne, f2Input, rhsTwo, f2Join, new LeftJoin());
Pipe result = new Each(resultsTwo, functionFields, new TestFunction(), Fields.REPLACE);
result Pipe should have expected result
}
}
Update the function
import cascading.flow.FlowProcess;
import cascading.operation.BaseOperation;
import cascading.operation.Function;
import cascading.operation.FunctionCall;
import cascading.tuple.Fields;
import cascading.tuple.TupleEntry;
public class TestFunction extends BaseOperation<Void> implements Function<Void> {
private static final long serialVersionUID = 1L;
private static final String DECIDING_FACTOR = "No";
private static final String DEFAULT_VALUE = "N/A";
Expected Fields: "F1DecidingFactor", "F1Output", "F2DecidingFactor", "F2Output"
public TestFunction() {
super(Fields.ARGS);
}
@Override
public void operate(@SuppressWarnings("rawtypes") FlowProcess process, FunctionCall<Void> call) {
TupleEntry arguments = call.getArguments();
TupleEntry result = new TupleEntry(arguments);
if (result.getString("F1DecidingFactor").equalsIgnoreCase(DECIDING_FACTOR)) {
result.setString("F1Output", DEFAULT_VALUE);
}
if (result.getString("F2DecidingFactor").equalsIgnoreCase(DECIDING_FACTOR)) {
result.setString("F2Output", DEFAULT_VALUE);
}
call.getOutputCollector().add(result);
}
}
Citations
This should solve your problem. Please let me know if this helps.