Each group of Pandas is randomly sampled
I have a data frame very similar to it, but with thousands of values :
import numpy as np
import pandas as pd
# Setup fake data.
np.random.seed([3, 1415])
df = pd. DataFrame({
'Class': list('AAAAAAAAAABBBBBBBBBB'),
'type': (['short']*5 + ['long']*5) *2,
'image name': (['image01']*2 + ['image02']*2)*5,
'Value2': np.random.random(20)})
I was able to find a way to randomly sample 2 values per image, per category, and per type with the following code:
df2 = df.groupby(['type', 'Class', 'image name'])[['Value2']].apply(lambda s: s.sample(min(len(s),2)))
I got the following result:
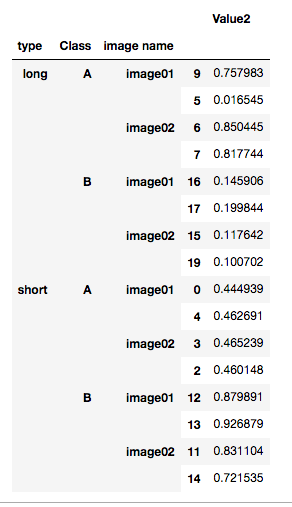
I’m looking for a way to subset the table to be able to randomly select random images (“image names”) based on type and category (and reserve 2 values for randomly selected images.
I want an Excel example of the output:
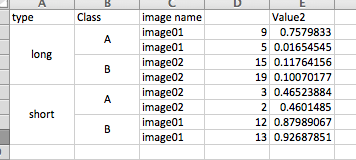
Solution
IIUC, the problem is that you don’t want to group the image name column, but if it’s not included in the group by, you’ll lose it
You can create the Grouby object first
gb = df.groupby(['type', 'Class'])
Now you can use list inference to interact with the Grouby block
blocks = [data.sample(n=1) for _,data in gb]
You can now connect blocks to reconstruct randomly sampled data frames
pd.concat(blocks)
Output
Class Value2 image name type
7 A 0.817744 image02 long
17 B 0.199844 image01 long
4 A 0.462691 image01 short
11 B 0.831104 image02 short
or
You can modify your code and add the column image name to groupby, like this
df.groupby(['type', 'Class'])[['Value2','image name']].apply(lambda s: s.sample(min(len(s),2)))
Value2 image name
type Class
long A 8 0.777962 image01
9 0.757983 image01
B 19 0.100702 image02
15 0.117642 image02
short A 3 0.465239 image02
2 0.460148 image02
B 10 0.934829 image02
11 0.831104 image02
Edit: Keep each set of images the same
I’m not sure you can avoid using an iterative process for this issue. You can just iterate through the groupby block, filter the groups, get random images and keep the name of each group the same, and then randomly sample from the remaining images like this
import random
gb = df.groupby(['Class','type'])
ls = []
for index,frame in gb:
ls.append(frame[frame['image name'] == random.choice(frame['image name'].unique())].sample(n=2))
pd.concat(ls)
Output
Class Value2 image name type
6 A 0.850445 image02 long
7 A 0.817744 image02 long
4 A 0.462691 image01 short
0 A 0.444939 image01 short
19 B 0.100702 image02 long
15 B 0.117642 image02 long
10 B 0.934829 image02 short
14 B 0.721535 image02 short