How to skip the first few rows of an Excel worksheet in Python… here is a solution to the problem.
How to skip the first few rows of an Excel worksheet in Python
I was able to successfully unmerge all cells in an Excel worksheet using openpyxl; However, I want to keep the first 7 rows of the worksheet. As shown below, the first 7 rows contain the merged cells.
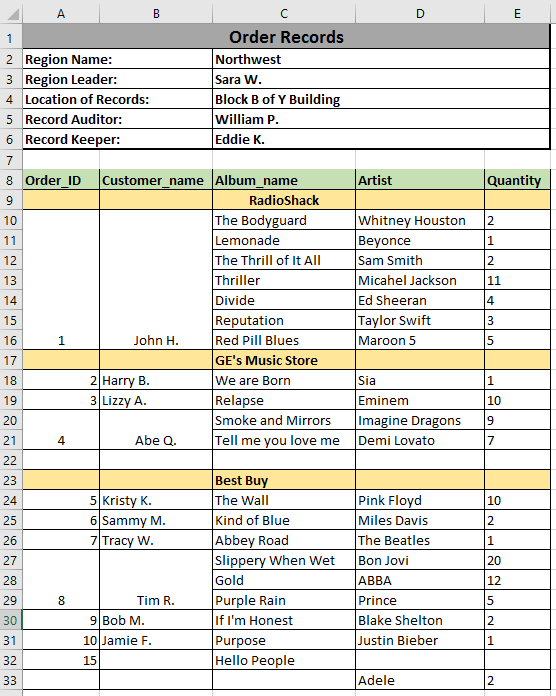
After I run the following code (find the merged cells and split them):
def fill_in(rows,first_cell,last_cell):
#Take first cell's value
first_value = first_cell.value
#Copy and fill/assign this value into each cell of the range
for tmp in rows:
cell = tmp[0]
print(cell) ##E.g. (<Cell 'Sheet1'. A1>,)
print(cell.value) ##E.g. Order Records
cell.value = first_value
wb2 = load_workbook('Example.xlsx')
sheets = wb2.sheetnames ##list of sheetnames
for i,sheet in enumerate(sheets): ##for each sheet
ws = wb2[sheets[i]]
range_list = ws.merged_cell_ranges
for _range in range_list:
first_cell = ws[_range.split(':')[0]] #first cell of each range
last_cell = ws[_range.split(':')[1]]
rows = ws[_range] #big set of sets; each cell within each range
fill_in(list(rows),first_cell,last_cell)
For reference, rows look like this:
((<Cell 'Sheet1'. A1>, <Cell 'Sheet1'. B1>, <Cell 'Sheet1'. C1>, <Cell 'Sheet1'. D1>, <Cell 'Sheet1'. E1>),)
This is what a new Excel worksheet looks like: the first 7 rows become cluttered.
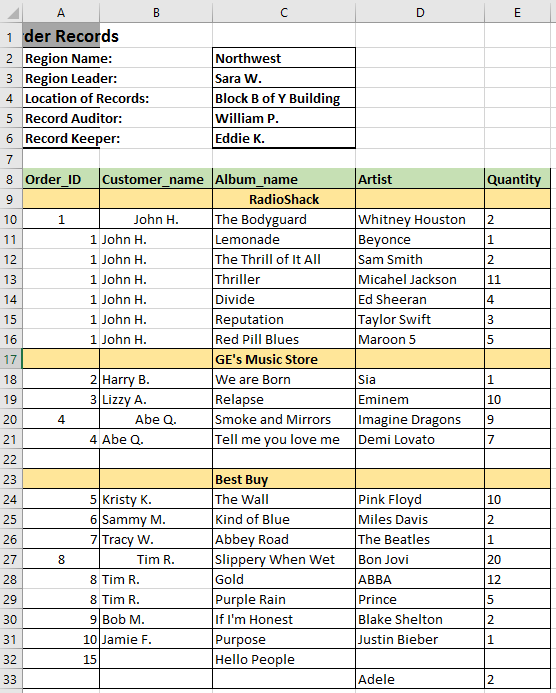
Considering my code above, what can I include/do to skip the first 7 rows of the Excel worksheet or exclude these rows from being merged?
Solution
merged_cell_ranges is a list, so you only need to start iterating after index 30 (6 rows * 5 columns).
for _range in range_list[30:]: