Is there a way to help make this Python logic run faster
I’ve been working on a solution to get data from PLC sensors using Python, and I’m able to calculate syntax using cppo, etc. This approach works well in terms of getting data from labels in a loop in a supposed serialization fashion.
To test this new Python cpppo solution, I’ve connected the machine running Python logic to the PLC through a VPN tunnel, and I have it poll a specific label/sensor. This tag also polls with different non-Python solutions connected to the local machine network and logs over Ethernet.
Question
Does anyone know of a way I can rewrite this simple code below where I can force it to poll 3 or even 4 times in a second? Is there anything else that might contribute to this?
- By contributing to “this”, I’m talking about “other” or “non-Python” methods that seem to log poll responses from the same tag 3 times a second and Python cpppo solutions that seem to only em> at a maximum of 2 times per second so when there are 3 weight values in a second, occasionally a weight is lost – sometimes only 2 per second, so it doesn’t always have 3 values a second, but sometimes there are 3 in a second.
Data
The returned sensor data is enclosed in square brackets, but the weight is expressed in grams and has decimal precision, with a small sample of the original data below.
[610.5999755859375]
[607.5]
[623.5999755859375]
[599.7999877929688]
[602.5999755859375]
[610.0]
Python code
Note: Python logic writes the sensor’s polling values to a csv file, but based on the system date and time via datetime.now() but before that, I convert the value to a string and then remove the square brackets str( x).replace('[','').replace(']','') uses the str() function.
from cpppo.server.enip.get_attribute import proxy_simple
from datetime import datetime
import time, csv
CsvFile = "C:\\folder\\Test\\Test.csv"
host = "<IPAddress>"
while True:
x, = proxy_simple(host).read("<TagName>")
with open(CsvFile,"a",newline='') as file:
csv_file = csv.writer(file)
for val in x:
y = str(x).replace('[','').replace(']','')
csv_file.writerow([datetime.now(), y])
#time.sleep(0.05)
Issues and test results
When I compare the csv file records captured by Python
with the records from other non-Python capture methods of the tag, the csv records generated by Python are sometimes lost, and often are.
Notable details (just in case).
There is a timestamp difference of one second or less between the two systems because they generate timestamps at the time of capture.
This particular sensor can spit out three values in a second, but not always; Sometimes one a second, or two a second, or none at all.
I think the other way is to use Java, but this code is not accessible to compare the logic.
I’m using Python version 3.6.5 (
v3.6.5:f59c0932b4, March 28, 2018, 16:07:46) [MSC v.1900 32-bit (Intel)]from Windows 10.
Results
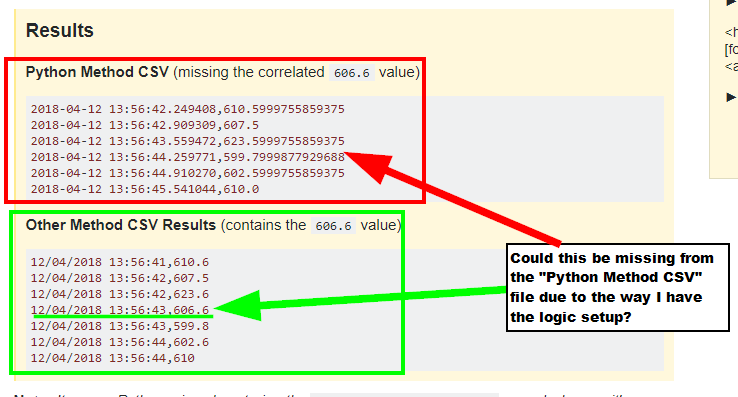
Python Method CSV (missing the correlated
606.6value)2018-04-12 13:56:42.249408,610.5999755859375 2018-04-12 13:56:42.909309,607.5 2018-04-12 13:56:43.559472,623.5999755859375 2018-04-12 13:56:44.259771,599.7999877929688 2018-04-12 13:56:44.910270,602.5999755859375 2018-04-12 13:56:45.541044,610.0Other Method CSV Results (contains the
606.6value)12/04/2018 13:56:41,610.6 12/04/2018 13:56:42,607.5 12/04/2018 13:56:42,623.6 12/04/2018 13:56:43,606.6 12/04/2018 13:56:43,599.8 12/04/2018 13:56:44,602.6 12/04/2018 13:56:44,610
Problem description: Python missed capturing 12/04/2018 13:56:43,606.6 record while it was from another system. I suspect this is due to some slight delay following this logic, as I only see it missing values compared to other non-Python captured files.
Solution
The key parts of the code are:
while True:
x, = proxy_simple(host).read("<TagName>")
with open(CsvFile,"a",newline='') as file:
for val in x:
# ...
In pseudocode:
forever:
create proxy
open output file
process values from proxy
You mentioned that the sensor may produce about 3 values per second. If you look at the implementation of read(), What it does is set up a new reader object and produce all the values from it.
You might think your code works like this:
- Create a proxy
- Open the output file
- Process value
- Go to 3
But actually, it’s probably like this:
- Create a proxy
- Open the output file
- Process value
- Go to 1
Every time you call read(), it produces a value that it knew at that time. It does not wait for any new values to arrive.
Try this refactoring:
source = proxy_simple(host)
with open(CsvFile,"a",newline='') as file:
while True:
for message in source.read("<TagName>"):
for val in message:
# ...
Another error in the original code is:
x, = proxy_simple(host).read("<TagName>")
If read() returns multiple values, you only need to use the first one. That’s why there are two for loops in the code I suggested above.
Then you will only open the input and output once each time the program runs, not once per message.