Python Pandas copies columns from one sheet to another without changing any data?
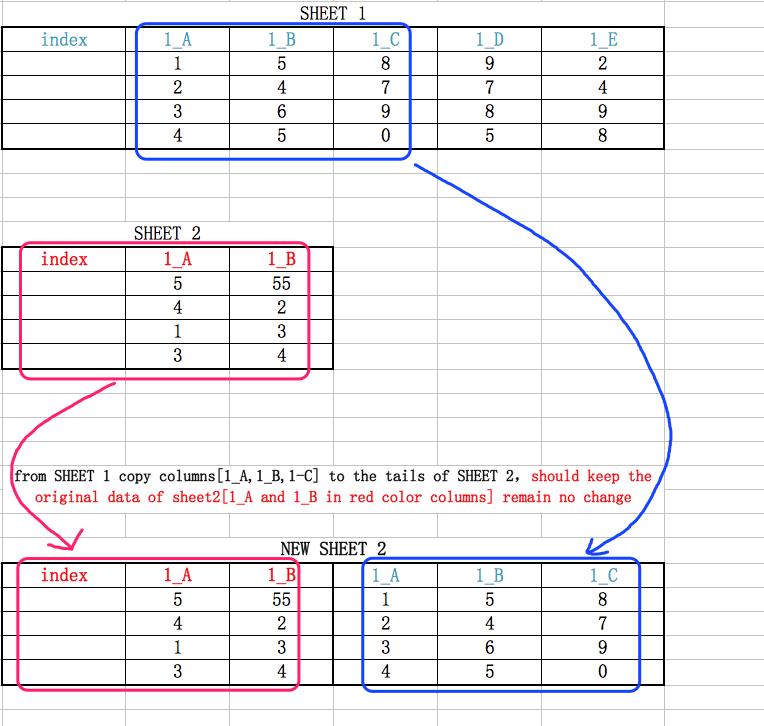
I have an excel file with two sheets. I want to copy 3 columns from the first worksheet to the second worksheet.
Note:
- The label names of the copied 3 columns have some duplication with the second table. But I should keep the original data of the second table without changing them.
I’ve tried a lot of methods. My best attempt so far is:
df_new_sheet2 = pd.concat([df_old_sheet2, df_three_of_sheet1], axis=1, join_axes=[df_old_sheet2.index])
But this is not the desired output.
If pandas can’t do that, can you recommend some other python packages that will work?
If I don’t describe the problem clearly enough, I’ll upload an image that might help more or less. Thank you for your answer~
Update [2017.07.24]:
I finally found my fault!
insert one column with index number Then, according to the resolution of b2002, everything will be fine. 🙂
Solution
This method uses Pandas and xlsxwriter
Settings (Create demo excel file):
import pandas as pd
df1 = pd. DataFrame({'1_A': [1,2,3,4], '1_B': [5,4,6,5],
'1_C': [8,7,9,0], '1_D': [9,7,8,5], '1_E': [2,4,9,8]})
df2 = pd. DataFrame({'1_A': [5,4,1,3], '1_B': [55,2,3,4]})
setup_dict = {'Sheet_1': df1, 'Sheet_2': df2}
with pd. ExcelWriter('excel_file.xlsx',
engine='xlsxwriter') as writer:
for ws_name, df_sheet in setup_dict.items():
df_sheet.to_excel(writer, sheet_name=ws_name)
(Start reading the existing excel file from here).
#Read your excel file, use "sheetname=None" to create a dictionary of
#worksheet dataframes. (Note: future versions of pandas will use
#"sheet_name" vs. "sheetname").
#Replace 'excel_file.xlsx' with the actual path to your file.
ws_dict = pd.read_excel('excel_file.xlsx', sheetname=None)
#Modify the Sheet_2 worksheet dataframe:
#(or, create a new worksheet by assigning concatenated df to a new key,
#such as ws_dict['Sheet_3'] = ...)
ws_dict['Sheet_2'] = pd.concat([ws_dict['Sheet_2'][['1_A','1_B']],
ws_dict['Sheet_1'][['1_A','1_B','1_C']]],
axis=1)
#Write the ws_dict back to disk as an excel file:
#(replace 'excel_file.xlsx' with your desired file path.)
with pd. ExcelWriter('excel_file.xlsx',
engine='xlsxwriter') as writer:
for ws_name, df_sheet in ws_dict.items():
df_sheet.to_excel(writer, sheet_name=ws_name)
You can use other methods to combine columns, such as joins (for example, using different suffixes to represent the original worksheet)
Because when excel file, all worksheets are converted to data frames
Read.
Edit (for new worksheets and unique column names…).
ws_dict = pd.read_excel('excel_file.xlsx', sheetname=None)
#Modify the Sheet_2 worksheet dataframe:
#(or, create a new worksheet by assigning concatenated df to a new key,
#such as ws_dict['Sheet_3'] = ...)
ws_dict['Sheet_3'] = ws_dict['Sheet_2'][['1_A','1_B']].join(ws_dict['Sheet_1'][['1_A','1_B','1_C']],
lsuffix='_sh2', rsuffix='_sh1', how='outer')
#Write the ws_dict back to disk as an excel file:
#(replace 'excel_file.xlsx' with your desired file path.)
with pd. ExcelWriter('excel_file.xlsx',
engine='xlsxwriter') as writer:
for ws_name, df_sheet in ws_dict.items():
df_sheet.to_excel(writer, sheet_name=ws_name)