PySpark(Python 2.7): How to flatten values after reduce
I’m reading a multiline log file using SparkContext.newAPIHadoopFile with custom delimiter. I’m ready anyway, reducing my data. But now I want to add the key to every line (entry) again, then write it to an Apache Parquet file, and then store it in HDFS.
This diagram should explain my problem. What I’m looking for is the red arrow, such as the last conversion before writing to the file. Any ideas? I tried flatMap, but timestamps and floating-point values result in different records.
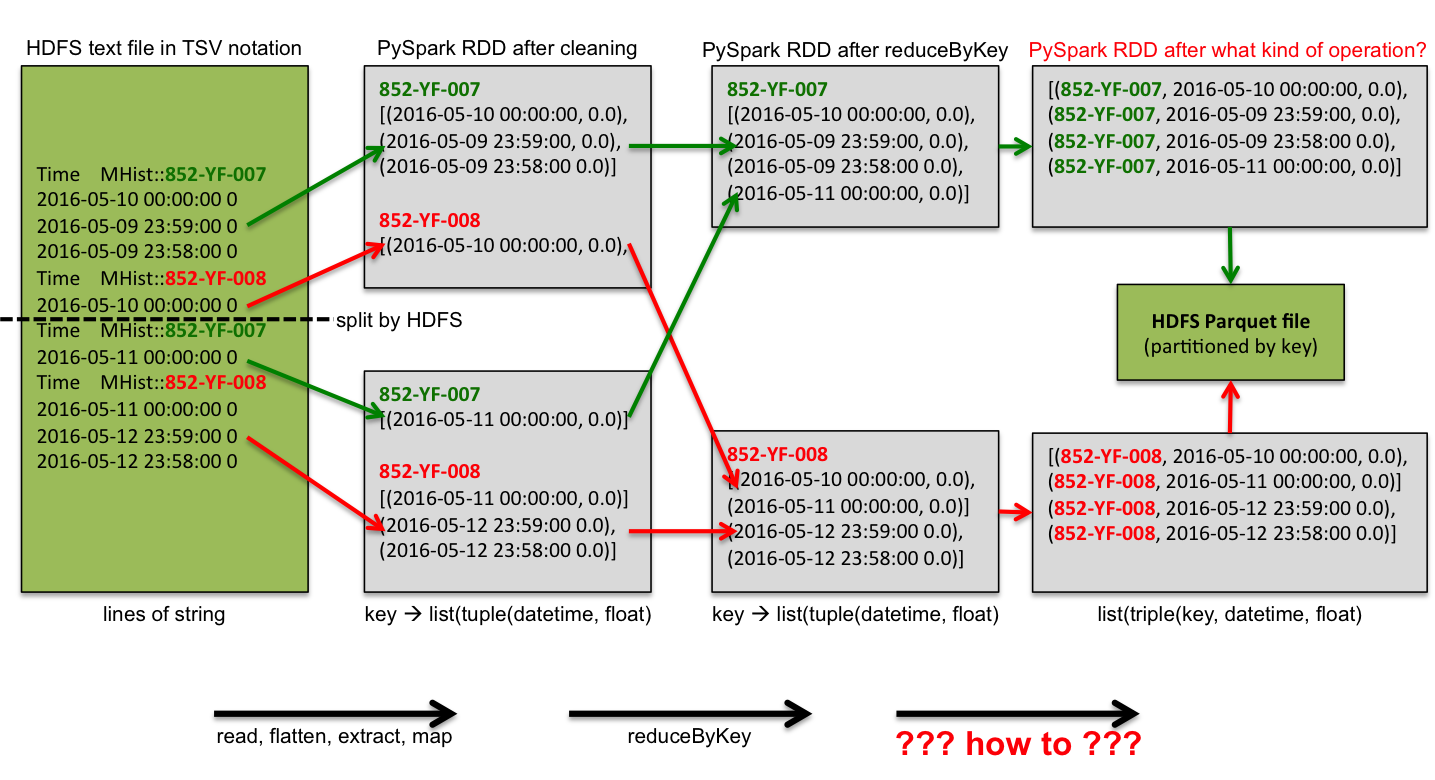
Python scripts can be downloaded here and samples text file here.
Solution
Simple list comprehension should be more than enough:
from datetime import datetime
def flatten(kvs):
"""
>>> kvs = ("852-YF-008", [
... (datetime(2016, 5, 10, 0, 0), 0.0),
... (datetime(2016, 5, 9, 23, 59), 0.0)])
>>> flat = flatten(kvs)
>>> len(flat)
2
>>> flat[0]
('852-YF-008', datetime.datetime(2016, 5, 10, 0, 0), 0.0)
"""
k, vs = kvs
return [(k, v1, v2) for v1, v2 in vs]
In Python 2.7, you can also use lambda expressions with tuple parameter unpacking, but this is not portable and is generally discouraged:
lambda (k, vs): [(k, v1, v2) for v1, v2 in vs]
Version independent:
lambda kvs: [(kvs[0], v1, v2) for v1, v2 in kvs[1]]
Edit:
If you only need to write partition data, you can convert directly to Parquet: without reduceByKey
(sheet
.flatMap(process)
.map(lambda x: (x[0], ) + x[1])
.toDF(["key", "datettime", "value"])
.write
.partitionBy("key")
.parquet(output_path))