8 character range
I work on a text file encoded in UTF-8 and read its contents in python. After reading the content, I split the text into a character array.
import codecs
with codecs.open(fullpath,'r',encoding='utf8') as f:
text = f.read()
# Split the 'text' to characters
Now, I’m iterating on each role. First, convert it to a hexadecimal representation and run some code on it.
numerialValue = ord(char)
I noticed that between all these characters, some characters were out of the expected range.
Expected max value – FFFF.
Actual character value – 1D463.
I translated this code into python. The original source code is from C# and its value ‘\u1D463’ is an invalid character.
Confused.
Solution
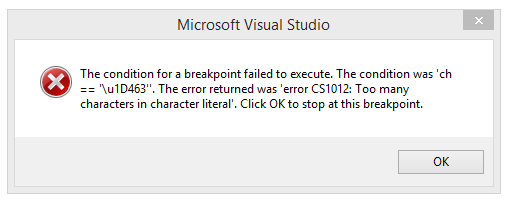
You seem to have escaped your Unicode code point (U+1D463) using \u instead of \U. The former requires four hexadecimal digits, while the latter requires eight hexadecimal digits. According to Microsoft Visual Studio:
The condition is ch == '\u1D463'
When I use this text in Python Interpreter, it doesn’t prompt, but it happily escapes the first four hexadecimal digits and prints 3: normally when running in cmd
>>> print('\u1D463')
ᵆ3
You encounter this exception: Expected Maximum - FFFF. Actual character value - 1D463 Because you are using an incorrect unicode escape, use \U0001D463 instead of \u1D463. The maximum value of a character code point in \u is \uFFFF and the maximum value in \U is \UFFFFFFFFF. Note the leading zeros in \U0001D463, \U exactly eight hexadecimal digits, \u exactly four hexadecimal digits:
>>> '\U1D463'
File "<stdin>", line 1
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 0-6: truncated \UXXXXXXXX escape
>>> '\uFF'
File "<stdin>", line 1
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 0-3: truncated \uXXXX escape