The need for execution order and caching
Let’s consider Python pseudocode snippets using Spark.
rdd1 = sc.textFile("...")
rdd2 = rdd1.map().groupBy().filter()
importantValue = rdd2.count()
rdd3 = rdd1.map(lambda x : x / importantValue)
In the DAG of the spark task, there are two branches, after the creation of rdd1. Both branches use rdd1, but the second branch (calculating rdd3) also uses rdd2's important Value.
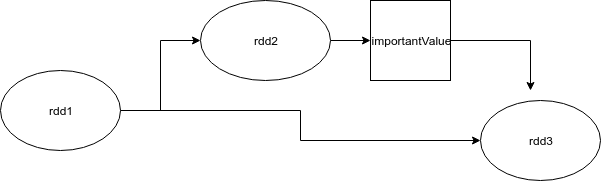
Am I right? If so, can we assume that rdd1 used to compute rdd3 is still being processed in memory? Or do we have to cache rdd1 to prevent it from being loaded repeatedly?
More generally, if the DAG looks like this:
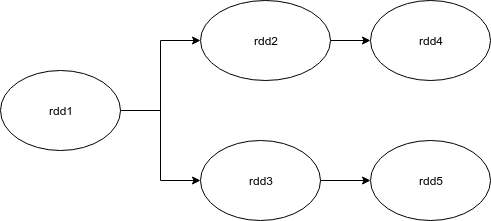
Can we assume that both branches are computed in parallel and use the same copy of rdd1? Or does the Spark driver compute these branches one after the other because these are two different phases? I know that before execution, the spark driver divides the DAG into phases and a more detailed logical part – tasks. Tasks within one stage can be computed in parallel because there is no shuffle phase in it, but what about two parallel branches in the image? I know all the intuitions that support RDD abstraction (lazy evaluation, etc.), but that doesn’t make it easier for me to understand. Please give me any advice.
Solution
I assume that DAG looks something like this: Am I right?
Yes.
If yes, can we assume that rdd1 used in computing rdd3 is still handled in memory?
No. Spark leverages lazy evaluation to process data. This means that nothing is calculated until it is needed. Nothing is stored unless explicitly stated.
Or we have to cache rdd1 in order to prevent repeated loading of that?
Specifically, you need to cache rdd1 to prevent the text file from being read twice.
More generally, if DAG looks like this: can we assume that both branches are computed pararelly and use the same copy of rdd1? Or Spark driver will compute these branches one after another, because these are two different stages?
These two branches are not processed in parallel because they have different pedigrees. Usually, no data is processed until action is taken. Whenever a result is needed (read, call an Action), all ongoing transformations and data processing of the current Action in a given lineage occur. After that, no data will exist in memory unless cache is called.
Check out this deck transformation and action explained